Custom vs Pre-Built AI Models: What’s the Best Approach for Your AI Product?

AI is now the norm, fully integrated across industries and reshaping customer expectations. It’s no longer just a buzzword or something to ‘dabble in’ – it’s essential.
Here’s a quick exercise: Look at your Product Management tool stack. How many tools now feature AI that wasn’t there a couple of years ago? How many rely entirely on AI? Chances are, most of your tools leverage AI in some way.
If AI is baked into everything you use, it might be time to consider it for your product too. But, don’t adopt AI just because others are doing it. It needs to address customer pain points, align with your business goals, and be the right fit for your product.
Building an AI product isn’t easy. It requires unique considerations and steps to follow that make it different from launching other products. That’s why we’ve created this comprehensive guide on managing AI products.
Co-authored by myself and ProdPad Co-founder Simon Cast, we cover everything you need to know. If you read one Product Management ebook this year, make it this one:

But for now, let’s explore one of the biggest, most impactful decisions you need to make when building an AI product: are you going to create your own AI model from scratch, or are you going to use an existing model?
What is an AI model?
An AI model is the powerhouse behind any AI-powered product. Think of it as the brain that processes information, recognizes patterns, and generates outputs based on the data it has been trained on. Without an AI model, your tool wouldn’t be able to analyze inputs, make predictions, or automate decisions – it would just be an empty shell 🐚.
AI Model Definition:
An AI model is the ‘brain’ of your AI tool, trained on data to recognize patterns, make predictions, and generate insights – all without human intervention.
AI models learn from massive datasets, identifying trends and patterns to improve their accuracy over time. The quality of your model directly impacts how well your AI product performs, whether it’s generating text, detecting anomalies, or personalizing user experiences. The better the data, the smarter the AI.
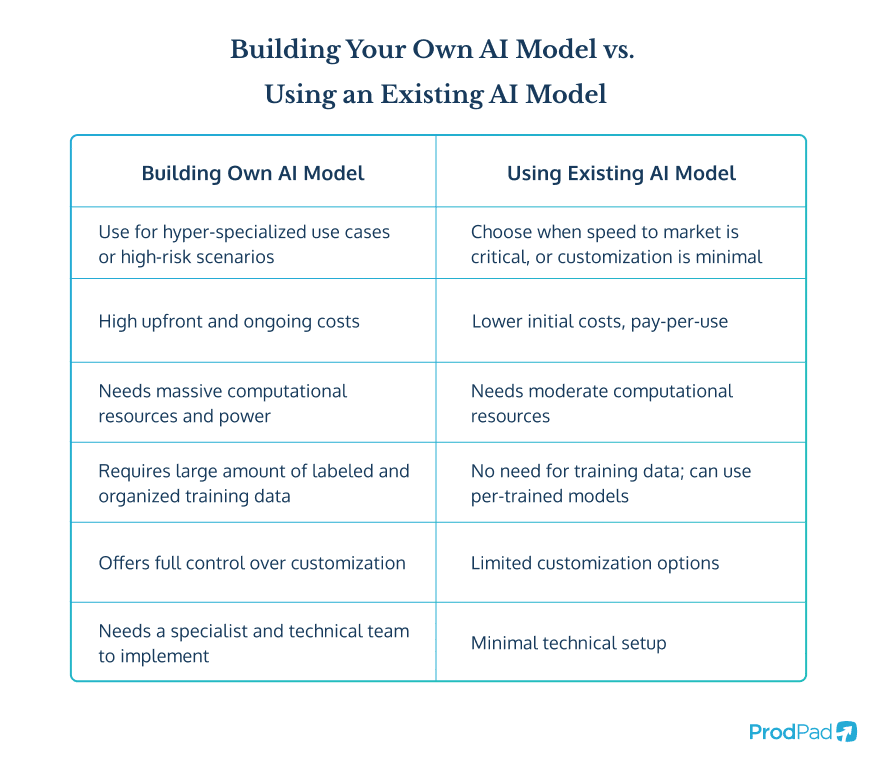
As an AI Product Manager, you need to decide whether to build your own AI model from scratch or leverage an existing one. Building your own gives you complete control and customization but requires significant expertise, time, and resources. Using a pre-trained model can save time and effort while still delivering strong results – if you choose the right one.
Let’s run through both options, making sure you understand the considerations for each approach.
Option 1: Building your own AI model 👷
Straight off the bat, it’s important to state that most Product Teams do not opt for this path. We want to be transparent from the jump. The reason for this is that building your own AI model is a significant undertaking, one that is only really worth the investment in a few, fairly rare cases.
With so many open-source LLMs available, it’s a far quicker and easier process to adopt an existing model and fine-tune it to suit your particular use case. Therefore, your decision to embark on the journey of creating your own AI model should only be taken when you’re certain an existing model will not serve your needs.
When should you build an AI model?
So when is it right to disregard existing open-source AI models and build your own? Well, this usually comes down to how specialized your product needs to be. Are you serving a very particular and niche use case? Is the intelligence needed very specific and not achievable through fine-tuning an existing model?
Here are some examples where building your own AI model is the way to go:
- Hyper-specialized intelligence: If your product serves a highly niche use case that can’t be achieved through fine-tuning an existing model, you may need to build your own.
Example: A tool that identifies plant or animal species from photos would require training on a precise dataset of images.
- Proprietary Data Requirement: If your product relies on exclusive, proprietary data that isn’t publicly available, an off-the-shelf model might not cut it. Open-source models are trained on general datasets, which means they won’t have direct knowledge of your unique data.
Example: A financial AI assistant designed to provide investment insights would require a custom model. Publicly available AI models wouldn’t have access to this confidential information and, therefore, couldn’t generate truly informed responses.
- Training vs. referencing data: There’s a big difference between training a model on your data and merely allowing it to reference that data. If you need the AI to internalize and learn from your dataset – rather than just pulling in information as part of a response – you’ll need to build and train your own model.
Example: A chatbot trained on proprietary support data can detect patterns and provide context-aware responses, unlike one that just references a static knowledge base.
- High-risk, high-impact use cases: If accuracy is critical and incorrect outputs could lead to severe consequences, a custom-trained model may be the best option.
Example: A radiology AI that identifies cancers from scans must be trained on a highly specialized dataset to ensure reliability. Inaccurate results could be life-threatening.
What to consider when building your own AI model?
If you feel like your product really DOES need its bespoke AI model, there are a few other things you need to consider before you dive face-first into this major endeavor.
Have you got enough training data?
Well, have you? You need A LOT of training data to build a viable AI product. Plus, having a lot of data isn’t enough; you also need:
- Surplus data that you can use to test the model
- Labeled and organized data that allows the model to understand it
Take one of our examples from earlier – a product that assesses radiography scans and spots cancers. We’ve already discussed the advantages of building your own model for this and training it with a vast series of different images. But this will only work if each image is labeled, telling the model whether it’s an image with cancer present or not.
That example would require a massive quantity of images fed into the model – both of scans with cancer present and scans without. And each and every one would need to be labeled so the model learns the distinction between cancer and cancer-free.
This leads to a lot of work!
Have you got the right team?
Building your own AI model means you’re getting into a major technical project here, and that requires very specialized knowledge and experience. You cannot embark on building your own AI model without some key roles on the team.
Those crucial roles include:
1️⃣ Data Scientists for model designing, training and evaluation
2️⃣ Data Engineers for data collection, pipelines and storage management
3️⃣ ML Engineers for deploying AI models to production
You should also consider:
- MLOps Engineers for automating and monitoring AI workflows
- A specialist AI Product Manager to devise and manage the product strategy
- AI Ethicist – this is genuinely a role that is starting to emerge. They work to ensure fairness, bias reduction and compliance
Have you got the computational power?
The next consideration is whether you have the oompf to run an AI model.
The computational power required for both the training and deployment of your own AI model is huge. Massive. Ginormous even.
Even the models at the smaller end of the spectrum will still need some hefty hardware behind them.
Let’s start by looking at the processing power you need to actually train a model.
Training requirements
The training of a machine learning model requires immense computational power. We can’t stress that enough.
This process involves running thousands or even millions of iterations of data through the model to adjust parameters and improve accuracy. You can’t do that with your laptop.
The hardware needed typically includes:
- GPUs (Graphics Processing Units): High-performance GPUs, such as NVIDIA A100, H100, or AMD MI250, are essential for deep learning due to their ability to handle parallel computations efficiently.
- TPUs (Tensor Processing Units): Designed specifically for AI workloads, TPUs (offered by Google) provide even greater efficiency for tensor operations in large-scale deep learning tasks.
- High-Core-Count CPUs: For traditional machine learning models and preprocessing large datasets, CPUs with multiple cores (e.g., AMD EPYC or Intel Xeon) can be necessary.
- Memory & Storage: Large RAM (64GB+) and fast SSDs/NVMe drives are essential for handling big datasets without significant slowdowns.
For small-scale models, cloud services like AWS (SageMaker), Google Cloud (Vertex AI), or Azure Machine Learning can provide on-demand access to powerful GPUs and TPUs, so that might be something to explore if expensive hardware purchases are not an option.
Once your model is trained, you’re still going to need a decent degree of power to deliver your AI experience through your product. Let’s look at what’s needed…
Hosting & inference requirements
Once trained, you need to deploy your AI model to serve predictions in real-time or batch-processing scenarios. Compared to training, you typically need less computational power at this stage, but again, that will depend on the complexity and latency requirements of your application.
At a minimum, you’re likely to need:
- CPUs for Basic Inference: Many AI models can run efficiently on high-performance CPUs for smaller workloads.
- GPUs for Real-Time AI: If the model needs to process high-throughput requests quickly (e.g., chatbots, real-time image recognition), deploying on a GPU-powered server ensures low-latency responses.
- Edge Devices: In cases where AI needs to run locally (e.g., IoT devices, mobile phones), specialized hardware like NVIDIA Jetson, Google Coral, or Apple’s Neural Engine in iPhones can be used.
- Cloud AI Services: Cloud providers offer AI inference-optimized services such as AWS Inferentia, Google Cloud AI Platform, or Azure ML Inference for scalable hosting without dedicated infrastructure.
Have you got the technical infrastructure to support building your own AI model?
It’s not just processing power that you’ll need in place if you want to build your own model. There’s the whole technical infrastructure.
As well as processing power, you need to have:
- Large-scale data storage: Your AI model will rely on large volumes of high-quality data. That requires proper data storage and management systems. You need databases, data lakes, data pipelines and versioning tools.
- Efficient monitoring and maintenance: You’ll need the right infrastructure in place to help you log and track system health and spot performance degradation over time. And potentially automated retraining pipelines that help you update the model training to improve any performance dips.
Are the costs feasible for the business?
Given everything we’ve said about computational power and data storage, cost is going to be a big factor when building your own AI model. Neither of those things come cheap!
So, before you decide on this path, you need to be certain that the business can sustain both the upfront costs involved in building and training the model, and the ongoing costs of hosting and running the AI in your application.
And remember, if your AI product is successful, those hosting costs will scale upwards. So, you need to anticipate the scalability of your costs and know whether that is feasible for the business and makes the product cost-effective.
When it comes to cost, you need to balance what you buy in terms of power and storage with the acceptable performance level you need to achieve.
If any of that has put the frighteners up you (and we wouldn’t blame you – building your own AI model is a MAJOR technical undertaking), then it’s time to think about the alternative – using an existing AI model.
Option 2: Using an existing AI model 🔗
Using an existing AI model is certainly the most widespread approach when creating and launching an AI product. There are a number of reasons why that is:
✅ It’s cheaper
✅ It’s faster
✅ It doesn’t require vast quantities of data
✅ You can spend all your time developing your application rather than building the model
There are a decent number of open-source LLMs or API-based models available for use now, so you even have options when you take this route. We’ll cover the different models as well as how to choose between them a little later.
But first, let’s make sure you’re clear on exactly how this works…
How does using an existing AI model work?
If you want to offer an AI product, or AI functionality but building your own AI model does not make sense (as it rarely does), then you’re going to need to lean on one of the many existing AI models and build your application on top of that.
There are two approaches to choose from:
1️⃣ Self-hosting an open source LLM (Large Language Model)
2️⃣ Using an API-based LLM
Self-hosting an open source LLM
With this route you will need to consider computational power as you’re hosting the model yourself. Although you won’t need the extreme power required to actually build and train a model, you are going to need some degree of processing power and data storage if you want to handle the hosting in-house.
How you host the model is up to you. It can be on-premise (using GPUs), cloud-based (through Amazon AWS, Google Cloud, Azure etc), or you can use edge deployment, running smaller models on devices like Jetson Nano or Coral TPU.
The advantages of self-hosting are a greater level of control over the model, with the ability to customize certain elements. This is also a better route if data privacy is likely to be a major concern for you and your users, as you’re keeping all the data on your own server.
You should consider self-hosting if:
- Data privacy is paramount
- You have the existing infrastructure and processing power, or know you can finance it
- You need the highest level of customization of the model
Open source LLM options include:
- Meta’s LLaMA
- Mistral AI
- Falcon
- Bloom
- GPT-J & GPT-NeoX
API-based LLM
The alternative to hosting a model is to simply use the API of an existing model, hosted elsewhere, to make calls and provide your responses.
Here, you have no heavy infrastructure requirements, and you can typically get set up much faster.
However, you will be sacrificing control and customization of the model, and you will need to think about the costs associated with each and every API call.
You should consider an API-based ‘managed service’ if:
- Speed to market is paramount
- You can make your AI product or feature work through fine-tuning rather than actual customization of the model
- You can support scalable per-request costs as your product usage increases
API-based LLM options included:
- OpenAI’s GPT-4 / GPT-3.5
- Anthropic’s Claude
- Google’s Gemini
- Mistral AI’s API
What to consider when using an existing AI model?
I’m guessing that using an existing AI model is starting to sound like the right direction for your product, but what do you need to think about before making the final decision?
Let’s run through the common considerations so you understand what you’re getting into.
The costs
You have to pay for this! If you’re going down the API-based route, someone else is footing the bill to power and host the model, plus all the work and data they put in to build and train the model. So, they’re going to charge you for usage. Obviously.
You need to think about how you handle those costs. How do you ensure this is scalable for the business? This normally comes down to your AI monetization strategy.
AI Monetization: How to Approach AI Pricing
If you’re leaning more towards the self-hosted option then you need to make sure you’ve weighed the costs of hosting up against the cost of the API-based option to make sure it’s worth it.
Our CTO here at ProdPad, Simon Cast, crunched the numbers on this and believes you’re looking at around $13,000 of OpenAI API calls per month before it becomes more economical to host a model yourself.
Performance issues
You are completely beholden to the performance and stability of a third-party model. It’s as simple as that. There will likely be outages, downtime, and slow responses, and you’ll need to have considered that in advance and think about how you’ll handle that.
You can deal with the risk of sub-optimal performance through technical solutions or customer care.
Technical solution 🔌
You could consider a process that routes the API call to a different AI model provider if one fails. This is probably worth looking at if you think dips in performance would be unacceptable to your users or significantly impact your product’s overall perception and performance.
Customer care solution 🫂
The alternative is to make sure you set the right expectations of the AI’s performance across the touchpoints you have with users – from your marketing messaging to your in-app copy and Customer Support communications.
It’s also worth training your customer-facing teams so they know how to explain any AI performance issues with users, mitigating any major complaints or frustrations.
Dependency on a third party
If you use someone’s AI model to power your product or features, you’re introducing a dependency on a third party and that comes with risk to the business.
Since the performance of an external AI model will have such an impact on the performance of your product, you’re removing a significant amount of control from the business. This can make business leaders and board members nervous.
However, the chances are that this wouldn’t be the first time you’re reliant on a third party. Your business is likely to have a number of different third-party risk points – from hosting providers to CRM tools.
The use of third-party providers is fairly standard practice these days; what’s important is knowing how to spread that risk and have mitigation measures in place.
The model doesn’t remember
This is an important point. When using existing AI models, don’t forget that the model won’t remember! These AI models are ‘stateless’ – they have no memory built into the model itself. If memory needs to be captured, it has to happen within the application you build.
So, if you need memory – for example, if you need recall for a conversation bot – you’ll need to build that into your product.
Knowledge cut-off
With most existing AI models, there will be a knowledge cut-off date that represents the end date of the data the model was trained on. In simple terms, the model won’t have learnt anything new since that cut-off date.
You won’t have the ability to patch a model with new or custom information. So, if it’s important that your AI tool is taking custom information into account, then you’re going to have to layer on retrieval-augmented generation (RAG).
This involved capturing new knowledge (maybe from the prompt the user has given, or from some context data they’ve included) and placing it in a store. You’ll then need to give the AI a way of drawing on the information in this store to inform their response.
Remember, when using an existing model, you will never be able to put new information into the model; you can only fine-tune it with system instructions, providing other content sources for them to draw on each and every time they’re called upon to complete a task.
You need to fine tune
Do not underestimate the amount of work involved in fine-tuning an existing AI model to ensure the outputs it creates in your product are relevant and accurate.
Although you can’t train the model, you can overlay system instructions within your application that feed the model with guidance on how the output should be presented.
You need to factor in considerable time to feed the model with prompts and ideal response examples to help hone and optimize the outputs, ensuring your application of this AI model is relevant and valuable in the context of your product and your users.
A great example of this being done well is our very own ProdPad CoPilot ✨. CoPilot is an AI tool specifically designed for Product Management and Product Teams, and, as such, the team here at ProdPad invested close to two years priming, fine-tuning, and prompting the AI model behind CoPilot, painstakingly feeding it system instructions based on real Product Team experiences.
Read more about the process that went into building CoPilot and see what you can apply to your own AI product.
What will you choose?
So those are your two options when it comes to your AI model. Are you going to build one from scratch, or are you going to take advantage of the open source options available to you?
Whatever you choose, this isn’t your only consideration. A lot goes into building an AI tool or adding Ai into your current product. This isn’t something you should rush.
At ProdPad, we’re one of the first Product Management tools to use AI to make our product even better. We know a thing or two about AI products and have put together this complete guide to building AI products, drawing from our many years of experience leveraging AI.
If you’re an AI Product Manager, or are building an AI product, it’s essential reading. Check it out for free!